Saturday, April 24, 2010
If you want to find say xyz@gmail.com is invisible or not. Open your gtalk application and type the email address or username in top search textbox.

Click the profile, it opens in new window as usual.
Click on the down arrow button in the top right corner of the window, and you can see Go off the record link there.

Message appears in red text if your friend is really offline

If the person is invisible no message appears
Use this trick to identify invisible friends from gtalk!
Saturday, April 10, 2010
But the regular gtalk version provided by google does not allow you to be in invisible mode when you are logged in.

gtalk-modes
As seen in the image above you can either set your gtalk to busy, show current music track or any custom message as your gtalk status message.
Invisible In Google Talk With Google Talk Labs Edition
In order to get invisible with gtalk only then you need to install a some what different version of gtalk called gtalk labs edition.
What is Gtalk Labs Edition?
Google Talk, Labs Edition is an experimental release of the Google Talk client. It has many of the same great features as the Google Talk Gadget, including instant messaging, emoticons, and group chat. Google Talk Labs Edition also includes new desktop notifications from Gmail, Calendar and Orkut.
You will need to first download gtalk labs edition from here, and install it.
After running and logged in to gtalk labs edition, you will find the option to set your status to invisible mode.

gtalk labs edition-modes
But google talk labs edition is not as good as google talk!
Create Desktop Shortcut To Chat With Your Favorite Gtalk Buddies
0 comments Posted by Deepak at 1:53 PMA useful trick for google talk users, which allows you to create desktop shortcuts for launching the chat window.
For example, I frequently chat with some person xyz@gmail.com in google talk, so every time I want to chat with him I would need to search and type his name or gmail id in search bar or you can also enable to see all online contacts by enabling the scrollbar.

So, if you don’t want to search every time the same person you frequently chat, you can create desktop shortcuts with the following target paths.
gtalk:chat?jid=xyz@gmail.com [starts a chat]
gtalk:call?jid=xyz@gmail.com [starts a call]
Saturday, January 16, 2010
Here are two unexplored features in GMail that will can make your Gmail inbox spam proof.
Gmail Easter Egg 1:
GMail allows email aliases and unlike Yahoo mail which lets you create just one extra email alias, GMail lets you create infinite number of aliases.
An email sent to paris.hilton@gmail.com or paris.hilton+fans @gmail.com or paris.hilton+blog@gmail.com will all be redirected to one common email address and that is paris.hilton@gmail.com.
Gmail does not recognize characters after the PLUS symbol but the gmail search filter can distinguish between the different address and you can therefore redirect these email to separats gmail folders or apply different labels.
So all emails with the TO: address as paris.hilton+blog@gmail.com (coming from her blog readers) can be automatically redirected to a blog folder in gmail and she can safely trash them when her inbox is approaching the 2 GB limit.
Gmail Easter Egg 2:
Gmail cannot recognize dots or periods in email addresses or the user names - that means an address like paris.hilton@gmail.com is the same as paris.hi.lton@gmail.com or paris...hilton@gmail.com.
This is actually a bug than a feature but you can again exploit it to have different kind of email address in your forum signatures.
Keep in mind that hyphens (-) and underscores (_) can't be used in a Gmail address. Also, gmail user names are case insensitive, so it doesn't matter if you enter upper case or lower case letters.
Tuesday, September 8, 2009
Recently, I had to send a mail to all my friends.
So I was searching for a method to do it.
That's when I found this pretty useful video in youtube!
Saturday, July 25, 2009
![]()
Gtalk is the Widley Used Messenger all over the Internet ,People are now switching to Gtalk slowly and slowly leaving yahoo messenger due to some enhanced feature.So its necessary for new gtalk users to know more about Gtalk ,for this we have created a short Gtalk Tutorials that will help users while surfing gtalk .
Send Bold Text: Text embedded between two * characters is displayed as bold text. Example: This is a *bold* statement.
Send Italics Text: Text embedded between two _(underscore) characters is displayed as italics text. Example: This is an _italics_ statement
Insert Line Breaks: If you want to have a message that spans multiple paragraphs, just hold shift and hit enter
Send mail: Press F9 to send a mail to the contact with whom you are chatting
Restore Google Talk Window: Press Windows Key + Esc to restore Google Talk window from system tray
Call a Contact: Press F11 to start a voice call with the chat contact and F12 to end the voice call
Insert Line Breaks – If you want to have a message that spans multiple paragraphs, just hold shift and hit enter. You can add as many new lines as you want to create.
Switch Windows – Hitting tab will cycle through open windows. It will select minimized conversations, to expand them just hit enter. If you just want to cycle through IM’s and don’t care about the buddy list, control-tab will do that and will automatically expand a minimized conversation if you settle on one.
Length Of A Single Message – A message can be max 32767 characters long.
Use Keyboard shortcuts while talking in Gtalk ,It will make yours work fast and talk Easy ,Below are some keyboard shortks for Gtalk User.
- Ctrl + 5 (KeyPad) - Selects all the text typed.
- Ctrl + 1 (NumPad) - It goes at the end of the last line.
- Ctrl + 7 (NumPad) - It goes at the begin of the last line.
- Ctrl + F4 – It closes the current window.
- Alt + F4 - It closes the current window.
- Alt + Esc – It Minimize the current open window.
- Windows + ESC – Open Google Talk (if it’s minimized, or in the tray).
- F9 - Open Gmail to send an email to the current contact.
Nickname & Status Message:You can’t change your nickname in a way that other people will see it change. Every nickname in the Google Talk contactlist is the part that is before @gmail.com (only the alphabetical characters are used) or the name you chosen for your GMail account. To change the nickname need to go to your Gmail account and change the name there. Choose Settings, Accounts, and then Edit info. Click on the second radio button, and enter your custom name. As a result all of your emails will have that nick as well, there is no way to seperate the two. You can add a website in your custom message, it will be clickable when someone opens a conversation window with you.
- F11 – It initiates a telephonic call with your friend.
- F12 – It cancels a telephonic call.
- Esc – It closes the current window
How To Make Conference Calls:To have conference calls in Gtalk: Open up a copy of Google Talk on all computers with which you wish to conference. After one copy is opened make a new shortcut for Google Talk but at the end of the target add /nomutex. If you installed it to the default folder then your shortcut should read
“C:\Program Files\Google\Google Talk\googletalk.exe” /nomutex.
Open Second instance of the software on every user’s computer.After this start a chain: User 1 should connect on one instance to user 2. User 2 will connect on his second instance to user 3. User 3 will connect using his second instance back to user 1. With this chain everyone is connected to everyone.
Login to multiple Google Talk accounts simultaneously with a very easy hack. Follow these steps
- Create a shortcut of Google Talk messenger on your desktop or any other preferred location .(To create a shortcut, right click on your Google Talk messenger application select Send To–>Desktop(create shortcut) )
- Right click on the Google Talk messenger icon and select Properties option
- Modify target location text “c:\program files\google\google talk\googletalk.exe” /startmenu to
“c:\program files\google\google talk\googletalk.exe” /nomutex
- Click Ok and you are done with this .
Contacts: Don’t need to say yes or no when someone wants to add you as a friend; you can simply ignore it, the request will go away. (On the other hand, someone with whom you chat often will automatically turn to be your friend, unless you disable this).
Wierd: The Gmail account ‘user@gmail.com’ can’t be invited as your friend.
Sunday, June 21, 2009
Here's a wonderful website, which lets you find out amongst two keywords, which is the most searched.
Here it shows a short fight between two stickmen and then it shows the result.
A good way to find out which keyword is searched more in Google.
Google Fight
Monday, March 2, 2009

Wednesday, December 3, 2008
We already knew that working for Google had certain advantages, but, believe me, this giant of the search motor takes the welfare of its employees seriously. As shown by this visit to Google's European center in Zurich.
Decompression (stress) capsule that is impermeable to sound and light.
Moving around - A slide allows quick access from different floors. There are also poles available, they are similar to the ones used in fire stations.
Food - Employees can eat all they want from a vast choice of food and drink.
Work Station - Each employee has at least two large screens. There are 4-6 Zooglers per office.
Innovation - Large boards are available just about everywere because "ideas don't always come when seated in the office" says one of Googles managers.
Leisure - Pool tables, video games etc. are available in many areas.
Communication - On each floor, there are private cabin areas where employees can attend to personal affairs.
Technical Support - Problem with your computer ? No problem ... Bring it to this area where drinks are available while it is being fixed ...
Health - Professional masseurs (eusses) available.
Rest - This room provides massage chairs that you control ... while you view relaxing aquariums ... !!!
The Library
Thursday, September 25, 2008

Today is the tenth anniversary of google.
And hence the post is special!
Wednesday, September 3, 2008
Google has launched a new browser called google chrome. The interface of the browser is pretty simple. But it's damn fast.
Descrpition by google:
Google Chrome is a browser that combines a minimal design with sophisticated technology to make the web faster, safer, and easier.
Download link: http://www.google.com/chrome

Screenshot of google chrome
An article about google chrome from the google blog:
At Google, we have a saying: “launch early and iterate.” While this approach is usually limited to our engineers, it apparently applies to our mailroom as well! As you may have read in the blogosphere, we hit "send" a bit early on a comic book introducing our new open source browser, Google Chrome. As we believe in access to information for everyone, we've now made the comic publicly available -- you can find it here. We will be launching the beta version of Google Chrome tomorrow in more than 100 countries.
So why are we launching Google Chrome? Because we believe we can add value for users and, at the same time, help drive innovation on the web.
All of us at Google spend much of our time working inside a browser. We search, chat, email and collaborate in a browser. And in our spare time, we shop, bank, read news and keep in touch with friends -- all using a browser. Because we spend so much time online, we began seriously thinking about what kind of browser could exist if we started from scratch and built on the best elements out there. We realized that the web had evolved from mainly simple text pages to rich, interactive applications and that we needed to completely rethink the browser. What we really needed was not just a browser, but also a modern platform for web pages and applications, and that's what we set out to build.
On the surface, we designed a browser window that is streamlined and simple. To most people, it isn't the browser that matters. It's only a tool to run the important stuff -- the pages, sites and applications that make up the web. Like the classic Google homepage, Google Chrome is clean and fast. It gets out of your way and gets you where you want to go.
Under the hood, we were able to build the foundation of a browser that runs today's complex web applications much better. By keeping each tab in an isolated "sandbox", we were able to prevent one tab from crashing another and provide improved protection from rogue sites. We improved speed and responsiveness across the board. We also built a more powerful JavaScript engine, V8, to power the next generation of web applications that aren't even possible in today's browsers.
This is just the beginning -- Google Chrome is far from done. We're releasing this beta for Windows to start the broader discussion and hear from you as quickly as possible. We're hard at work building versions for Mac and Linux too, and will continue to make it even faster and more robust.
We owe a great debt to many open source projects, and we're committed to continuing on their path. We've used components from Apple's WebKit and Mozilla's Firefox, among others -- and in that spirit, we are making all of our code open source as well. We hope to collaborate with the entire community to help drive the web forward.
The web gets better with more options and innovation. Google Chrome is another option, and we hope it contributes to making the web even better.
So check in again tomorrow to try Google Chrome for yourself. We'll post an update here as soon as it's ready.
Posted by Sundar Pichai, VP Product Management, and Linus Upson, Engineering Director
Article source: http://googleblog.blogspot.com/2008/09/fresh-take-on-browser.html
Atlast google has entered the browser war, instead of supporting Mozilla it's good that google has started it's own browser.
I have already started using this browser. I feel the difference instantly (it gives high speed browsing). You too can try!
Friday, March 21, 2008
Google has included invisible mode feature in GMail Chat last month(Feb 22, 2008). This feature allows you to appear offline and still chat with your friends unlike MSN Messenger. I feel that this is one of the best feature in Yahoo Messenger which is now made available to us in GMail Chat. Please note that this feature is not availble on GTalk Clients. Check out GMail’s Official Blog for more information.
Hope this invisible status is reaches gtalk soon.
Thursday, November 22, 2007
A Googlebot is a search bot used by Google. It collects documents from the web to build a searchable index for the Google search engine.
If a webmaster wishes to restrict the information on their site available to a Googlebot, or another well-behaved spider, they can do so with the appropriate directives in a robots.txt file.and by adding a metatag with meta name as Googlebot and meta content as no follow.Googlebot requests to Web servers are discernible from their user-agent string 'Googlebot'.
GOOGLEBOT

Googlebot has two versions, deepbot and freshbot. Deepbot, the deep crawler, tries to follow every link on the web and download as many pages as it can to the Google indexers. It completes this process about once a month. Freshbot crawls the web looking for fresh content. It visits websites that change frequently, according to how frequently they change. Currently Googlebot only follows HREF links and SRC links.
Googlebot discovers pages by harvesting all of the links on every page it finds. It then follows these links to other web pages. New web pages must be linked to from another known page on the web in order to be crawled and indexed.
A problem which webmasters have often noted with the Googlebot is that it takes up an enormous amount of bandwidth. This can cause websites to exceed their bandwidth limit and be taken down temporarily. This is especially troublesome for mirror sites which host many gigabytes of data. Google provides "Webmaster Tools" that allow website owners to throttle the crawl rate.
Article idea:Wikipedia
Monday, November 5, 2007
After a long time I have made a big post.
This post demanded that size....
If you aren’t interested in learning how Google creates the index and the database of documents that it accesses when processing a query, skip this description.
Google runs on a distributed network of thousands of low-cost computers and can therefore carry out fast parallel processing. Parallel processing is a method of computation in which many calculations can be performed simultaneously, significantly speeding up data processing. Google has three distinct parts:
Googlebot, a web crawler that finds and fetches web pages.
The indexer that sorts every word on every page and stores the resulting index of words in a huge database.
The query processor, which compares your search query to the index and recommends the documents that it considers most relevant.
Let’s take a closer look at each part.
1. Googlebot, Google’s Web Crawler
Googlebot is Google’s web crawling robot, which finds and retrieves pages on the web and hands them off to the Google indexer. It’s easy to imagine Googlebot as a little spider scurrying across the strands of cyberspace, but in reality Googlebot doesn’t traverse the web at all. It functions much like your web browser, by sending a request to a web server for a web page, downloading the entire page, then handing it off to Google’s indexer.
Googlebot consists of many computers requesting and fetching pages much more quickly than you can with your web browser. In fact, Googlebot can request thousands of different pages simultaneously. To avoid overwhelming web servers, or crowding out requests from human users, Googlebot deliberately makes requests of each individual web server more slowly than it’s capable of doing.
Googlebot finds pages in two ways: through an add URL form, www.google.com/addurl.html, and through finding links by crawling the web.

When Googlebot fetches a page, it culls all the links appearing on the page and adds them to a queue for subsequent crawling. Googlebot tends to encounter little spam because most web authors link only to what they believe are high-quality pages. By harvesting links from every page it encounters, Googlebot can quickly build a list of links that can cover broad reaches of the web. This technique, known as deep crawling, also allows Googlebot to probe deep within individual sites. Because of their massive scale, deep crawls can reach almost every page in the web. Because the web is vast, this can take some time, so some pages may be crawled only once a month.
Although its function is simple, Googlebot must be programmed to handle several challenges. First, since Googlebot sends out simultaneous requests for thousands of pages, the queue of “visit soon” URLs must be constantly examined and compared with URLs already in Google’s index. Duplicates in the queue must be eliminated to prevent Googlebot from fetching the same page again. Googlebot must determine how often to revisit a page. On the one hand, it’s a waste of resources to re-index an unchanged page. On the other hand, Google wants to re-index changed pages to deliver up-to-date results.
To keep the index current, Google continuously recrawls popular frequently changing web pages at a rate roughly proportional to how often the pages change. Such crawls keep an index current and are known as fresh crawls. Newspaper pages are downloaded daily, pages with stock quotes are downloaded much more frequently. Of course, fresh crawls return fewer pages than the deep crawl. The combination of the two types of crawls allows Google to both make efficient use of its resources and keep its index reasonably current.
2. Google’s Indexer
To improve search performance, Google ignores (doesn’t index) common words called stop words (such as the, is, on, or, of, how, why, as well as certain single digits and single letters). Stop words are so common that they do little to narrow a search, and therefore they can safely be discarded. The indexer also ignores some punctuation and multiple spaces, as well as converting all letters to lowercase, to improve Google’s performance.
3. Google’s Query Processor
The query processor has several parts, including the user interface (search box), the “engine” that evaluates queries and matches them to relevant documents, and the results formatter.
PageRank is Google’s system for ranking web pages. A page with a higher PageRank is deemed more important and is more likely to be listed above a page with a lower PageRank.
Google considers over a hundred factors in computing a PageRank and determining which documents are most relevant to a query, including the popularity of the page, the position and size of the search terms within the page, and the proximity of the search terms to one another on the page.
Indexing the full text of the web allows Google to go beyond simply matching single search terms. Google gives more priority to pages that have search terms near each other and in the same order as the query. Google can also match multi-word phrases and sentences. Since Google indexes HTML code in addition to the text on the page, users can restrict searches on the basis of where query words appear, e.g., in the title, in the URL, in the body, and in links to the page, options offered by Google’s Advanced Search Form and Using Search Operators (Advanced Operators).
Let’s see how Google processes a query.

Saturday, October 20, 2007
Google,anyone who uses net would be knowing this word.
The word became so powerful that it was included in the oxford dictionary.
But do we really use google to it's fullest off potentials?
I think no.
There are many additional features in google search.
I posted the features which I know.
There is a concept in google search called advanced searching.
And there are some advanced search operators.
You can improve your searches by adding those "operators" to your search terms in the Google search box.
Advanced search operators include:
1.Include Search
2.Synonym Search
3.OR Search
4.Domain Search
5.Numrange Search
6.Other Advanced Search Features
"+" search
Google ignores common words and characters such as where, the, how, and other digits and letters which slow down your search without improving the results. We'll indicate if a word has been excluded by displaying details on the results page below the search box.
If a common word is essential to getting the results you want, you can include it by putting a "+" sign in front of it. (Be sure to include a space before the "+" sign.)
For example, here's how to ensure that Google includes the "I" in a search for Star Wars, Episode.

Synonym search
If you want to search not only for your search term but also for its synonyms, place the tilde sign ("~") immediately in front of your search term.
For example, here's how to search for food facts and nutrition and cooking information:
 "OR" search
"OR" search To find pages that include either of two search terms, add an uppercase OR between the terms.
For example, here's how to search for a vacation in either London or Paris:
 Domain search
Domain search You can use Google to search only within one specific website by entering the search terms you're looking for, followed by the word "site" and a colon followed by the domain name.
For example, here's how you'd find admission information on the Stanford University site:
 Numrange search
Numrange searchThe numrange operator searches for results containing numbers in a given range. You can use Numrange to set ranges for everything from dates ( Willie Mays 1950..1960) to weights ( 5000..10000 kg truck). Just add two numbers, separated by two periods, with no spaces, into the search box along with your search terms, and specify a unit of measurement or some other indicator of what the number range represents.
For example, here's how you'd search for a DVD player that costs between $50 and $100:
 Fill in the blanks "*" search
Fill in the blanks "*" search Sometimes the best way to ask a question is to get Google to 'fill in the blank' for you. You can do this by adding an asterisk "*" in the part of the sentence or question that you want filled in.
For example, here's how you'd search for who invented the parachute:
 Other advanced search features
Other advanced search features
Language: specify in which language you'd like your results.
File format: specify the file format you'd like in your results
Date: restrict your results to the past three, six, or twelve month periods.
Occurrences: specify where your search terms occur on the page - anywhere on the page, in the title, or in the url.
Domains: search only a specific website, or exclude that site from your search.
Usage rights: specify the rights of usage you'd like in your results
SafeSearch: Eliminates adult sites from search results.
Page-specific: Specify pages that are similar or link to your page
Technology Search: find information related to Apple Macintosh, BSD Unix, Linux or Microsoft.
In addition to this i have found other useful features like using google as a calculator!!!!
Just type the expression you want to evaluate in the search box.(as you type in a calculator) And money value converter!!!!
And money value converter!!!!
Just type the currency you want to convert in the search box.
Friday, October 19, 2007

- First, create one copy of the Google Talk shortcut on your desktop - leave the original intact.
- Right click on this shortcut and choose Properties. The Target box will show you the path of the EXE for Google Talk - something like "C:\Program Files\Google\Google Talk\googletalk.exe"
- Change this to: "C:\Program Files\Google\Google Talk\googletalk.exe" /nomutex and click OK.
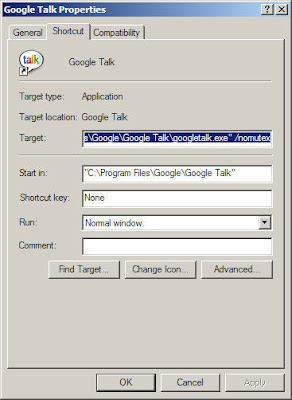
I too had a similar problem.And found this as the solution after surfing through the internet.
When we don't know something......What do we do?
We search in the internet using some search engine.
But how does the the search engine search for you?
What is the hidden mechanism behind the searching?
How Internet search engines work?
Here is the answer........
Looking at the Web
Searches Per Day:Top 5 Engines
Google - 250 million
Overture - 167 million
Inktomi - 80 million
LookSmart - 45 million
FindWhat - 33 million
*Feb. 2007.
When most people talk about Internet search engines, they really mean World Wide Web search engines. Before the Web became the most visible part of the Internet, there were already search engines in place to help people find information on the Net.
Programs with names like "gopher" and "Archie" kept indexes of files stored on servers connected to the Internet, and dramatically reduced the amount of time required to find programs and documents. In the late 1980s, getting serious value from the Internet meant knowing how to use gopher, Archie, Veronica and the rest.
Today, most Internet users limit their searches to the Web, so we'll limit this article to search engines that focus on the contents of Web pages.
An Itsy-Bitsy BeginningBefore a search engine can tell you where a file or document is, it must be found. To find information on the hundreds of millions of Web pages that exist, a search engine employs special software robots, called spiders, to build lists of the words found on Web sites. When a spider is building its lists, the process is called Web crawling. (There are some disadvantages to calling part of the Internet the World Wide Web -- a large set of arachnid-centric names for tools is one of them.) In order to build and maintain a useful list of words, a search engine's spiders have to look at a lot of pages.
How does any spider start its travels over the Web? The usual starting points are lists of heavily used servers and very popular pages. The spider will begin with a popular site, indexing the words on its pages and following every link found within the site. In this way, the spidering system quickly begins to travel, spreading out across the most widely used portions of the Web.
"Spiders" take a Web page's content and create key search words that enable online users to find pages they're looking for.
WEB SPIDER CHART
Google.com began as an academic search engine. In the paper that describes how the system was built, Sergey Brin and Lawrence Page give an example of how quickly their spiders can work. They built their initial system to use multiple spiders, usually three at one time. Each spider could keep about 300 connections to Web pages open at a time. At its peak performance, using four spiders, their system could crawl over 100 pages per second, generating around 600 kilobytes of data each second.
Keeping everything running quickly meant building a system to feed necessary information to the spiders. The early Google system had a server dedicated to providing URLs to the spiders. Rather than depending on an Internet service provider for the domain name server (DNS) that translates a server's name into an address, Google had its own DNS, in order to keep delays to a minimum.
When the Google spider looked at an HTML page, it took note of two things:
The words within the page
Where the words were found
Words occurring in the title, subtitles, meta tags and other positions of relative importance were noted for special consideration during a subsequent user search. The Google spider was built to index every significant word on a page, leaving out the articles "a," "an" and "the." Other spiders take different approaches.
These different approaches usually attempt to make the spider operate faster, allow users to search more efficiently, or both. For example, some spiders will keep track of the words in the title, sub-headings and links, along with the 100 most frequently used words on the page and each word in the first 20 lines of text. Lycos is said to use this approach to spidering the Web.
Other systems, such as AltaVista, go in the other direction, indexing every single word on a page, including "a," "an," "the" and other "insignificant" words. The push to completeness in this approach is matched by other systems in the attention given to the unseen portion of the Web page, the meta tags.
Meta TagsMeta tags allow the owner of a page to specify key words and concepts under which the page will be indexed. This can be helpful, especially in cases in which the words on the page might have double or triple meanings -- the meta tags can guide the search engine in choosing which of the several possible meanings for these words is correct. There is, however, a danger in over-reliance on meta tags, because a careless or unscrupulous page owner might add meta tags that fit very popular topics but have nothing to do with the actual contents of the page. To protect against this, spiders will correlate meta tags with page content, rejecting the meta tags that don't match the words on the page.
All of this assumes that the owner of a page actually wants it to be included in the results of a search engine's activities. Many times, the page's owner doesn't want it showing up on a major search engine, or doesn't want the activity of a spider accessing the page. Consider, for example, a game that builds new, active pages each time sections of the page are displayed or new links are followed. If a Web spider accesses one of these pages, and begins following all of the links for new pages, the game could mistake the activity for a high-speed human player and spin out of control. To avoid situations like this, the robot exclusion protocol was developed. This protocol, implemented in the meta-tag section at the beginning of a Web page, tells a spider to leave the page alone -- to neither index the words on the page nor try to follow its links.


{kind=link}